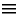
2. Классы
2.1. Абстрактные типы данных
§ 4. Уровень абстракции. Во введении мы уже отмечали, что объектно-ориентированное программирование обеспечивает меньший по сравнению с другими подходами9 семантический разрыв между представлением задачи на естественном языке мышления человека и представлением задачи на языке программирования. Теперь мы подробно остановимся на этом вопросе с технической точки зрения. Рассмотрим пример: необходимо написать программу, вычисляющую площадь треугольника по координатам его вершин. Проанализируем следующий код на C#:
public static void Main (string[] args)
{
// --- 1 этап. Запрос данных у пользователя и сохранение их
// --- в массив вещественных чисел t.
// Запрашиваем у пользователя строку координат через пробел.
string input = Console.ReadLine();
// Преобразуем строку координат в массив, разделяя исходую строку по пробелам.
string[] inputCoords = input.Split(' ');
// Преобразуем массив чисел из строк string в числа double.
double[] t = new double[inputCoords.Length];
for (int i = 0; i < inputCoords.Length; i++)
{
t[i] = double.Parse(inputCoords[i]);
}
// --- 2 этап. Расчет длин сторон треугольника.
double a = Math.Sqrt((t[2] - t[0]) * (t[2] - t[0]) +
(t[3] - t[1]) * (t[3] - t[1]));
double b = Math.Sqrt((t[4] - t[2]) * (t[4] - t[2]) +
(t[5] - t[3]) * (t[5] - t[3]));
double c = Math.Sqrt((t[4] - t[0]) * (t[4] - t[0]) +
(t[5] - t[1]) * (t[5] - t[1]));
// --- Расчет площади по формуле Герона.
double p = (a + b + c) / 2;
double square = Math.Sqrt(p * (p - a) * (p - b) * (p - c));
// --- 3 этап. Вывод площади пользователю.
Console.WriteLine(square);
}
Это решение демонстрирует подход, применявшийся на ранних этапах развития языков программирования. Работая над задачей, программист на уровне мышления оперирует следующими абстракциями: фигуры (треугольники), их свойства (периметр, длины сторон), алгоритмы расчета (формула вычисления длины отрезка, формула Герона). Но какие абстракции используются в приведенном коде? Только переменные базовых типов и инструкции. Соответственно, программа состоит из 1) вещественных чисел, массивов вещественных чисел, строк, массивов строк и 2) синтаксически не сгруппированных и не разделенных инструкций. Покажем, к каким проблемам приводит такая организация кода.
Применяя только переменные базовых типов, программист каждый раз, работая с кодом, осознанно или неосознанно проходит путь от низкоуровневых абстракций кода к высокоуровневым абстракциям мышления. Например: «Мне нужна ордината Y вершины B треугольника ABC… Координаты вершин хранятся в массиве вещественных числе t, при этом ординаты – в нечетных позициях… Соответственно, чтобы получить искомое значение, нужно вычислить индекс в массиве по формуле i = 2 * [индекс вершины B] + 1… Индекс вершины B равен 1… 2 * 1 + 1 = 3… Значит, ордината вершины B хранится в элементе массива вещественных чисел t[3].» Эти «размышления» демонстрируют проблему низкоуровневой модели данных.
Теперь рассмотрим, к чему приводит отсутствие синтаксической группировки и разделения инструкций. Что имеется в виду? С точки зрения организации кода и данных мы имеем один глобальный набор данных (переменных) и один неструктурированный блок кода (последовательность команд). Обсудим каждую из этих особенностей.
Фраза «один глобальный набор данных» значит, что весь код имеет доступ ко всем данным (переменным). Например, переменная inputCoords, объявленная в начале кода и необходимая только для обработки введенных пользователем данных и сохранения их в массив вещественных чисел t, видна всему последующему коду, где она заведомо не понадобится. Такая избыточная область видимости, то есть часть кода, где мы можем обратиться к некоторой переменной, приводит к ряду проблем. Во-первых, и это главная проблема, рано или поздно кто-то использует эту переменную там, где ее использовать не предполагалось. Это может создать побочный эффект, когда блок кода изменяет значение или полагается на значение переменных, связь с которыми этого блока кода никто не ожидает. Что приведет или к некорректной работе этого блока кода, если переменную изменят, не учитывая, где и как она используется, или к некорректной работе другого кода, если блок изменит переменную, а другой код, ее использующий, не будет этого знать. Во-вторых, избыточная область видимости синтаксически неудобна: имя резервируется в начале кода и не может быть использовано в других частях. Конечно, мы технически можем взять уже объявленную переменную и использовать ее для других целей, но это совершенно недопустимый подход, так как он усложняет понимание программы и неизбежно приводит к побочным эффектам. Каждая переменная должна использоваться строго для одной цели на протяжении всего времени жизни.
Вторая особенность, связанная с организацией инструкций в приведенном примере – «один неструктурированный блок кода». Мы имеем в виду, что код не структурирован с точки зрения языка программирования. В приведенном фрагменте мы с помощью комментариев выделили логически автономные разделы. Однако наличие такого рода комментариев всегда обозначает проблему, так как подобное разбиение должно реализовываться на уровне языка. Иначе структура оказывается очень хрупкой, так как она не обеспечивается синтаксически и легко разрушается: ничто не мешает программисту проигнорировать комментарии и обратиться из одного блока в другой или смешать их логику.
Таким образом, отмеченные две особенности – общие данные и общий код – приводят к одной и той же проблеме: возникновению множества явных или неявных зависимостей между логически не связанными частями программы. Как следствие, программист, работая над некоторым фрагментом кода, вынужден помимо основной задачи иметь ввиду множество других, не относящихся к нему, фрагментов, которые влияют на его код или на которые может повлиять его код. Обратим внимание, мы говорим, что рано или поздно возникнут логически необоснованные связи. Но зададимся вопросом: можем ли мы тем не менее попытаться избежать этих проблем, оставаясь в рамках концепции «вся программа – это один блок кода плюс один блок данных»? С одной стороны – да. Так, в приведенном примере разные части, отделенные комментариями, независимы и по факту, используют минимально необходимый объем данных из других частей. Однако мы уже отметили фундаментальную проблему: это может быть легко разрушено (на практике – будет), так как не подкрепляется никакими возможностям и ограничениями языка. Программист снова сталкивается с семантическим разрывом: он думает о частях программы, как о независимых, хотя они такими не являются на уровне языка.
Таким образом, и в вопросе модели данных, и в вопросе структурирования кода низкий уровень абстракции языка приводит к тому, что значительная часть усилий разработчика уходит не на решение основной задачи, а на преодоление разрыва в уровнях абстракции.
Объектно-ориентированное программирование предлагает подход, основанный на тезисе, что для человека наиболее естественным и простым является объектное представление. Конечно, этот тезис не безусловный, мы вернемся к его критике в заключении. Однако, как бы то ни было, на протяжении практически трех десятилетий именно ООП в том или ином виде остается главным подходом к разработке программного обеспечения.
В последующих параграфах мы последовательно рассмотрим эволюцию языков программирования, движимую стремлением преодолеть обозначенную проблему семантического разрыва на пути к одной из базовых концепций ООП – абстрактным типам данных. Решение задачи с треугольником, рассмотренное, в настоящем параграфе условно обозначим как 1 этап.
Конечно, этапы, которые мы будем рассматривать, несколько условны в том смысле, что концептуально большинство идей формулировались еще в 70-х годах. Однако они относительно точно отражают тенденции в развитии практически широко используемых в то или иное время языков программирования. Кроме того, выделение некоторой историчности всегда позволяет лучше определить причины введения в языки программирования тех или иных технических возможностей.
§ 5. Процедурное программирование. В примере из предыдущего параграфа мы использовали два вида абстракций: встроенные типы данных и инструкции кода. В процедурном программировании вводится новый вид абстракций – процедура. Читатель, вероятно, знает, что процедура – это не только способ сгруппировать последовательность команд, но, главное, – скрыть реализацию от пользователя процедуры (от вызывающего кода)10. Скрыть в том смысле, что вызывающий код видит только имя процедуры, ее параметры и возвращаемое значение, но никак не зависит от ее реализации, не может обратиться к отдельным строкам внутри процедуры и не может обратиться к локальным переменным процедуры.
Перепишем программу из предыдущего параграфа, используя процедурный подход. Реализуем три метода: Square, Length и SquareGeron (в C# процедуры называются методами, к вопросу терминологии мы вернемся позже):
// Расчет площади треугольника с координатами вершин, заданными в массиве.
float Square (float[] coords)
{
float a = Length (coords[0], coords[1], coords[2], coords[3]);
float b = Length (coords[2], coords[3], coords[4], coords[5]);
float c = Length (coords[4], coords[5], coords[0], coords[1]);
return SquareGeron (a, b, c);
}
// Расчет расстояния между двумя точками с координатами (x0, y0) и (x1, y1).
float Length (float x0, float y0, float x1, float y1)
{
return Math.Sqrt ( (x1 – x0) * (x1 – x0) + (y1 – y0) * (y1 – y0) );
}
// Расчет площади треугольника по формуле Герона длинам сторон a, b, c.
float SquareGeron (float a, float b, float c)
{
float p = (a + b + c) / 2;
return Math.Sqrt (p * (p – a) * (p - b) * (p - c));
}
Такое объединение кода с используемыми им данными, при котором другие части кода не имеют доступа к этим данным, называется инкапсуляцией. Например, в приведенном решении в методе Square используются локальные переменные для хранения рассчитанных длин сторон – a, b, c. Эти переменные не видны и не доступны извне метода. Точно так же внешний код может вызывать только весь метод целиком, задав значения параметров, но не может обратиться к отдельным строкам метода. Такая изоляция позволяет избежать зависимости внешнего кода от реализации процедуры: изменение реализации с сохранением ее сигнатуры11 не потребует изменения во внешнем коде. Таким образом, процедура выступает как абстракция (абстракция алгоритма), позволяя нам абстрагироваться от деталей, не нужных для решения основной задачи. Приведем концептуальное определение инкапсуляции [Буч 3]:
Инкапсуляция (encapsulation) – сокрытие реализации абстракции от пользователей абстракции.
Инкапсуляция на уровне процедур сегодня кажется естественным решением, однако следует отметить, что это было существенным шагом в эволюции языков программирования.
Тем не менее процедурный подход не вполне преодолевает семантический разрыв, который мы обсуждали в предыдущем параграфе. Какие проблемы сохраняются в приведенном решении?
Во-первых, у нас остается низкоуровневая модель данных. Треугольник в программе – это все также шесть не связанных друг с другом вещественных чисел.
Во-вторых, хотя в списке абстракций на уровне кода и появились алгоритмы, на практике этого недостаточно. «Процедуры сами по себе не предоставляют удовлетворительно богатого словаря абстракций» [Лисков 9]. Программист будет домысливать и строить из процедур более высокоуровневые объекты, которые не находят отражения в коде.
Условно обозначим процедурное программирование (в рассмотренном объеме) как 2 этап эволюции языков программирования.

На следующем этапе языки стремятся частично преодолеть первую названную проблему – сохраняющуюся низкоуровневую модель данных.
§ 6. Пользовательские структуры данных. Достаточно давно языки программирования поддерживают возможность определения структур данных.
Структура данных – синтаксически связанные данные.
Примером встроенной структуры данных являются массивы. Напомним, что массив (array) – это последовательность переменных одного типа, адресуемых индексом. Элементы массива связаны синтаксически в том смысле, что мы обращаемся к ним по одному и тому же имени, но по разным индексам. Элементы также могут быть связаны семантически в том смысле, что программист, как правило, группирует не просто произвольные элементы одного типа в один массив, а элементы, имеющие некоторую смысловую связь. Кроме того, структуры данных, как правило (это уже зависит от реализации языка) группируют данные и физически, так, например, элементы массива в памяти размещаются последовательно друг за другом. Следующий код на C#, создает и заполняет массив из шести вещественных чисел.
float[] triangle = new float[6];
for (int i = 0; i < triangle.Length; i++)
{
triangle[i] = i * 2;
}
На рисунке приведено распределение памяти в результате выполнения этого кода:
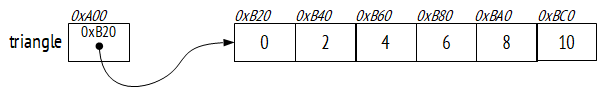
Отметим, что переменная triangle обозначает ячейку памяти, в которой хранится адрес блока памяти с элементами массива. Мы вернемся к этой особенности ниже. Сейчас обратим внимание на используемые на рисунке обозначения, мы будем применять и далее в книге. Ячейки памяти мы будем обозначать прямоугольниками (конечно, читатель понимает, что речь идет об оперативной памяти компьютера во время выполнения программы). Имена переменных, обозначающих эти ячейки в программе, будем подписывать рядом с соответствующими прямоугольниками. Значения ячеек будем записывать внутри прямоугольника. Если значение ячейки – адрес другой ячейки, то мы будем показывать это стрелкой, указывающей на адресуемую ячейку. На приведенном рисунке для большей наглядности мы показали и адреса ячеек (гипотетические), в дальнейшем мы их писать не будем.
Помимо массивов языки могут предоставлять и другие встроенные структуры данных. Однако они всегда представляют объекты низкого уровня абстракции. Для преодоления проблемы низкоуровневой модели данных в первом приближении используется механизм пользовательских структур данных, то есть структур, объявляемых программистом. Пользовательская структура, по сути, представляет объявляемый программистом новый тип данных, позволяющий синтаксически сгруппировать несколько переменных.
В C# пользовательская структура данных создается с помощью ключевого слова class и имеет следующий синтаксис12, показанный на примере структур для хранения координат одной точки и для хранения центра и радиуса круга:
// Структура для хранения точки синтаксически
// группирует координаты точки.
сlass Point
{
public float X;
public float Y;
}
// Структура для хранения круга синтаксически
// группирует радиус и центр круга.
// При этом центр круга, в свою очередь, – структура Point.
class Circle
{
public float R;
public Point Center;
}
Пишется ключевое слово class, далее следует имя структуры (имя определяемого пользователем нового типа данных). Именем может быть любое незарезервированное слово, удовлетворяющее требованиям к именам переменным. В C# принято называть типы с большой буквы. Далее в фигурных скобках перечисляются через точку с запятой объявления переменных, входящих в состав структуры, перед каждым объявлением указывается ключевое слово public, его назначение мы рассмотрим несколько позже. Переменные, входящие в состав структуры могут быть как встроенных, так и пользовательских (другие структуры) типов.
Таким образом, вместо того, чтобы объявить две независимых переменных float x; float y, мы объявляем одну переменную Point p, включающую в себя переменные X и Y. Для доступа к группируемым переменным используется оператор «точка»: p.X, p.Y. В C# эти составные части структуры называются полям (field). По аналогии с тем, как мы создаем массив из двух чисел для хранения координат (структура, не связанная с семантикой), мы создаем переменную типа Point (структура, связанная с семантикой). Разберите следующий пример:
float[] pointCoords = new float[2];
pointCoords[0] = 1;
pointCoords[1] = 2;
Point point = new Point();
point.X = 1;
point.Y = 2;
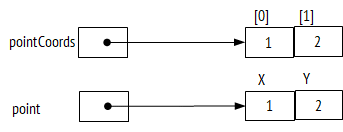
Синтаксис создания переменной пользовательского типа аналогичен синтаксису создания массива: используется ключевое слово new и далее имя типа с круглыми скобками. Сама переменная пользовательского типа называется объектом или экземпляром класса. В следующей главе мы детально разберем эти термины и синтаксис создания объектов.
Обратим внимание, что и переменная pointCoords, и переменная point обозначают ячейки, в которых хранится адрес объекта данных: в первом случае — это массив, во втором - структура Point. Соответственно, когда мы пишем point.X = 1, выполняется переход по адресу, хранимому в ячейке point, и уже там в поле с именем X записывается значение 1. Если же мы работаем с локальной переменной и присваиваем ей значение – float x = 1 – то происходит другой процесс: переменная x обозначает ячейку, в которой непосредственно хранится значение, поэтому значение 1 записывается сразу в эту ячейку.
float x = 1;
float y = 2;
В обоих случаях мы говорим «обозначает», имея в виду, что переменная – это лишь имя в программе некоторой ячейки памяти и при компиляции оно заменяется на адрес этой ячейки. Более того, это и есть определение переменной в программировании:
Переменная (variable) – именованная область памяти.
В C# переменные, которые обозначают ячейку, непосредственно хранящую значение, называются значимыми (value) переменными. Переменные же, обозначающие ячейку, содержащую адрес области памяти, где хранятся непосредственно данные, называются ссылочными (reference) переменными. Вид переменной в C# определяется ее типом. Так, все встроенные типы, кроме строк – значимые типы: int, long, float, double, decimal, byte, char, bool. Строка string, массивы и пользовательские типы class – ссылочные типы.
Мы можем использовать объявленный тип в своем коде как обычный тип, соответственно, мы можем теперь представлять треугольник не как массив из шести чисел, а как массив из трех точек:
float Square (Point[] vertices)
{
float a = Length (vertices[0], vertices[1]);
float b = Length (vertices[1], vertices[2]);
float c = Length (vertices[2], vertices[0]);
return SquareGeron (a, b, c);
}
float Length (Point p0, Point p1)
{
return Math.Sqrt ( (x1 – x0) * (x1 – x0) + (y1 – y0) * (y1 – y0) );
}
float SquareGeron (float a, float b, float c)
{
float p = (a + b + c) / 2;
return Math.Sqrt ( p * ( p – a) * ( p -b) * (p-c));
}
Данный подход можно развить – создать класс треугольник Triangle, который будет абстракцией треугольника:
class Triangle
{
public Point A;
public Point B;
public Point C;
}
float Square (Triangle t)
{
float a = Length (t.A, t.B);
float b = Length (t.B, t.C);
float c = Length (t.C, t.A);
return SquareGeron (a, b, c);
}
Triangle t = new Triangle();
float sq = Square(t);
Уровень абстракции, на котором работает программа стал значительно выше. Мы уже оперируем не обезличенными массивами, а структурами с именами, соответствующими предметной области. Вспомните «размышления» программиста, которые мы приводили, демонстрируя различия в уровнях абстракции в § 4. Теперь этот процесс выглядит значительно лучше: «Мне нужна ордината Y вершины B треугольника ABC… t.B.Y – вот она.» Абстракции в программе оказываются ближе к абстракциям мышления.
Зафиксируем использование пользовательских структур данных как 3 этап развития языков программирования в анализируемой нами эволюции.

Хотя мы существенно продвинулись в плане уровня абстракции модели данных, такой подход сопряжен с рядом проблем. Прежде всего – независимость друг от друга алгоритмов и данных. Например, площадь – это неотъемлемое свойство реального треугольника и концептуальной разницы между получением вершины A (t.A) и получением площади (t.Square?) нет. Однако в программе, эти две концепции независимы: одна абстракция – треугольник, хранит только его координаты, другая абстракция – процедура, вычисляет значение площади.
§ 7. Объединение данных с методами. Преодолеть разрыв между абстракциями данных и методов можно объединив их в одну абстракцию. Для этого нужно, чтобы пользовательская структура данных Triangle не только хранила данные треугольника, но и включала в себя методы манипулирования этими данными. В этом случае обычно используют не термин «структура данных», а термин «класс». Пока ограничимся упрощенным определением класса как структуры данных, объединенных с методами. Рассмотрим следующий код:
public class Point
{
public float X;
public float Y;
// Метод вычисляет расстояние от текущей точки, до указанной p.
// Метод объявлен внутри класса Point.
public float Length (Point p)
{
return Math.Sqrl ((X – p.X)*(X – p.X) +
(Y – p.Y)*(Y – p.Y));
}
}
Point p1 = new Point ();
p1.X = 1;
p1.Y = 1;
Point p2 = new Point ();
p2.X = 2;
p2.Y = 2;
float len = p1.Length(p2);
Вместо вызова метода float Length (Point p1, Point p2), как в ранее рассмотренном примере, мы объявили метод Length внутри класса Point. При этом метод связан с конкретным объектом, для которого он вызывается. Что это значит? Вместо Length (p1, p2) мы пишем p1.Length(p2). Такая запись обозначает, что метод Length вызывается для объекта p1 и внутри метода мы имеем доступ ко всем полям этого объекта. Так, мы обращаемся к полям X и Y объекта p2, указывая его имя (имя переменной-параметра p): p.X, p.Y. Но при этом для обращения к полям вызвавшего объекта мы просто пишем имя поля: X, Y. Таким образом, запись (X – p.X) обозначает что из значения поля X объекта p1 (для которого мы вызвали метод) мы вычитаем значение поля X объекта p2 (переданного как аргумент метода).
В действительности в любой метод класса неявно передается вызывающий объект, к которому можно обратиться внутри метода, используя ключевое слово this. Рассмотрите следующие примеры13:
public class Point
{
public float X;
public float Y;
// Метод вычисляет расстояние от текущей точки, до указанной p.
public float Length (/* неявный параметр метода: Point this, */ Point p)
{
return Math.Sqrl ((X – p.X)*(X – p.X) +
(Y – p.Y)*(Y – p.Y));
// эквивалентно:
// return Math.Sqrl ((this.X – p.X)*(this.X – p.X) +
// (this.Y – p.Y)*(this.Y – p.Y));
}
}
public class Circle
{
public Point Center;
public float R;
public float GetSquare( /* Circle this */ )
{
return Math.PI * R * R;
// эквивалентно:
// return Math.PI * this.R * this.R;
}
}
В некоторых случаях мы вынуждены явно использовать переменную this, например, если имя поля класса совпадает с именем параметра метода класса:
public class Point
{
public float x;
public float y;
public void Shift( /* Point this, */ float x, float y )
{
this.x += x;
this.y += y;
}
}
В приведенном коде происходит сокрытие имен (hiding): имена переменных-параметров метода Shift скрывают имена полей класса и использование этих имен в методе обозначает переменные-параметры, а не поля. Поэтому, если мы хотим обратиться к полям, мы вынуждены явно использовать ключевое слово this.
Одним из первых известных языков, реализовавших описанный на данный момент уровень «объектности» абстракций – объединения методов и данных – был язык Simula-67, один из источников C++.
Обозначим рассмотренный этап эволюции языков программирования на нашей диаграмме как четвертый.

Конечно, мы повысили уровень абстракции. Однако суть любой абстракции в выделении существенных для решаемой задачи вопросов и скрытии несущественных. Так, мы уже отмечали, что в случае методов реализация и локальные переменные скрываются от вызывающего кода. В рассмотренных же примерах все поля класса доступны не только методам этого класса, но и любому внешнему пользователю. В следующем параграфе мы покажем, почему такая доступность полей – серьезная проблема – и как она решается.
§ 8. Инкапсуляция на уровне классов. Рассмотрим две типовых ситуации, демонстрирующие, что доступность полей X и Y класса Point из предыдущего параграфа может привести к серьезным проблемам.
Первая: после того, как класс реализован и широко используется в коде, принимается решение изменить его реализацию, добавив систему координат и храня координаты в одном виде, но возвращая в другом. Более радикальный вариант: изменить тип данных или перечень полей, например, вместо двух полей хранить массив из двух элементов. Эти изменения потребуют корректировок многих частей кода – всех, которые обращаются к этим полям.
Вторая типовая ситуация: изменение полей извне, которое нарушает целостность состояния объекта. Например, положим у нас есть класс произвольного многоугольника Polygon, у которого есть метод расчета площади Square. Этот метод весьма нетривиален и его выполнение для большого числа точек может занимать ощутимое время. Если сценарии использования классов предполагают частое использование метода вычисления площади, то было бы удобно кэшировать вычисленное значение площади не извне класса, а в самом классе:
class Triangle
{
public float Sq = -1;
public float GetSquare()
{
if (Sq == -1)
{
// если еще не расчитана, то здесь расчитываем и сохраняем в Sq.
}
return Sq;
}
}
Однако ничто не мешает поменять поле Sq извне, нарушив целостность состояния класса.
Для решения подобных проблем объектно-ориентированные языки предоставляют механизм ограничения видимости полей класса только методами класса. В C# для этого используется ключевое слово private (закрытый). Ключевые слова public и private называют модификаторами доступа (access modifiers)14:
class Point
{
private float x;
public float GetX()
{
return x;
}
public float SetX(float x)
{
this.x = x;
}
}
// Использование:
Point p = new Point();
p.SetX (5);
// x == 5
float x1 = p.GetX();
// Ошибка компиляции: нельзя обратиться извне к закрытому полю.
float x2 = p.x;
Ограничение видимости полей реализует инкапсуляцию на уровне класса, позволяя скрывать закрытые поля класса от пользователей класса подобно тому, как локальные переменные метода скрываются от пользователя метода. Повторим уже приводившееся определение: инкапсуляция – сокрытие реализации абстракции от пользователей абстракции. Любая точка имеет характеристики X и Y – это существенные свойства абстракции. А вот как именно мы их храним в закрытых переменных – это вопрос реализации. Создав методы GetX/SetX для получения и изменения существенных свойств, мы скрываем от пользователя реализацию абстракции.
Обратим внимание, что ключевое слово private ограничивает видимость поля всеми методами того же класса, а не только того же объекта. Это значит, что метод класса может обратиться как закрытому (private) полю как того же объекта, для которого он был вызван (то есть объекта this), так и для другого объекта того же класса:
public class Point
{
private float x;
private float y;
// Метод вычисляет расстояние от текущей (this) точки, до указанной p.
public float Length (Point p)
{
// Метод имеет доступ как к закрытым (private) полям объекта,
// для которых он был вызван (this), так и к полям объекта p.
return Math.Sqrl ((this.x – p.x)*(this.x – p.x) +
(this.y – p.y)*(this.y – p.y));
}
}
Это поведение объясняется тем, что разработчик класса понимает его устройство и не будет некорректно менять другие объекты. Таким образом, принцип инкапсуляции не нарушается.
Обозначим добавление механизма инкапсуляции на уровне классов как 5 этап.

Введение механизма закрытых полей позволяет решить все обозначенные в предыдущих параграфах проблемы, приблизив уровень абстракции кода к уровню абстракции мышления человека. Таким образом, рисунок выше очерчивает набор возможностей, позволяющий реализовать пользовательский тип данных, который полноценно представляет некоторую абстракцию. Это и есть первая базовая идея ООП – абстрактные типы данных. В следующем параграфе мы сформулируем и обсудим определения абстрактного типа данных и класса.
§ 9. Определение. Мы уже не раз формулировали следующий принцип проектирования: «Одним из главных условий эффективного программирования является максимизация части программы, которую можно проигнорировать при работе над конкретными фрагментами кода» [Макконнелл 10]. Это вполне очевидное правило является одной из формулировок принципа сокрытия информации. Считается, что впервые он был сформулирован в 1970-х годах в работе [Парнас 16]15.
При этом мы отмечали, что всегда и на любом языке можно написать код, вполне удовлетворяющий принципу сокрытия информации. В конце концов, мы можем структурировать код с помощью комментариев. Другой вопрос в том, что крайне сложно добиться соблюдения этого принципа, если мы не опираемся на возможности языка. Основной такой возможностью является инкапсуляция – на уровне методов (процедурное программирование) или классов (объектно-ориентированное программирование). Именно инкапсуляция позволяет создавать в коде полноценные абстракции. Полноценные в том смысле, что пользователи этих абстракций (вызывающий код) ничего не знают и не могут знать о реализации используемой абстракции, то есть могут абстрагироваться от ненужных деталей, сосредоточившись только на необходимых. «Что мы хотим от абстракции – это механизма, который позволяет выражать существенные детали и скрыть несущественные детали. В случае программирования, то, как мы можем использовать абстракцию важно, а способ, которым абстракция реализована – неважен» [Лисков 9]. Следует ясно представлять соотношение обсуждаемых понятий: сокрытие информации, инкапсуляция и абстракция. «Сокрытие информации – это прежде всего вопрос проектирования программ; сокрытие информации возможно в любой правильно спроектированной программе вне зависимости от используемого языка программирования. Инкапсуляция, однако, это прежде всего вопрос разработки конкретного языка; абстракция может быть эффективно инкапсулирована только в том случае, если язык запрещает доступ к скрытой в абстракции информации.» [18]
Классы в том объеме технических возможностей, который мы обозначили в предыдущих параграфах, реализуют идею абстрактных типов данных. Приведем развернутое определение по [Пратт 18]:
Абстрактный тип данных – новый тип данных, определяемый программистом и включающий 1) определяемый программистом тип данных; 2) набор абстрактных операций над объектами этого типа; инкапсуляцию объектов этого типа таким образом, что пользователь нового типа не может манипулировать этими объектами, иначе как только с помощью определенных при разработке типа абстрактных операций.
Это вполне исчерпывающее и точное определение, хотя оно несколько устарело в части используемых терминов. Разберем его подробно. Первый элемент – «определяемый программистом тип данных» – это собственно перечень данных, хранимых объектами определяемого типа, то есть перечень полей класса. Такая формулировка обусловлена тем, что долгое время (этапы рассмотренной эволюции 1-2-3) под типом данных понималась исключительно структура без методов. Второй элемент – «набор абстрактных операций» – это набор методов класса, имеющих доступ к полям объекта. Абстрактная операция – это, в современной терминологии, метод. Отметим, что здесь слово «абстрактная», как и в термине «абстрактный тип данных» обозначает, что речь идет о некоторой абстракции предметной области16. Третье утверждение в определении – об инкапсуляции – описывает возможность объявления закрытых полей, к которым имеют доступ только методы класса. Отметим, что определение предполагает, что все поля всегда будут закрытыми. В этом смысле возможность объявления открытых полей является нарушением и отходом от «теоретически правильной» реализации. Далее мы увидим, что в большинстве случаев теория совпадает с практикой и такое нарушение нежелательно. Таким образом, можно переформулировать приведенное определение на современном языке:
Абстрактный тип данных (abstract data type) – новый тип данных, определяемый программистом и включающий 1) определяемый программистом перечень данных (полей типа); 2) набор методов, имеющих доступ ко всем полям типа; инкапсуляцию объектов этого типа таким образом, что пользователь нового типа не может манипулировать этими объектами, иначе как только с помощью определенных при разработки типа методов, то есть к полям типа имеют доступ только методы этого же типа.
В чем отличие класса и абстрактного типа данных? Можно ли сказать, что абстрактный тип данных – теоретическая концепция, а класс – это реализация этой концепции в языке программирования? С одной стороны, так и есть. Но, как мы уже говорили во введении, объектно-ориентированное программирование основывается на двух базовых идеях. Первая из них и есть абстрактные типы данных. А вторая – иерархические типы. Соответственно, сформулируем следующее определение:
Класс (class) в объектно-ориентированном программировании – это определяемый программистом тип данных, удовлетворяющий определениям: 1) абстрактного и 2) иерархического типа.
Детальному концептуальному и техническому разбору иерархических типов посвящен раздел 3 книги. В настоящем разделе, в последующих главах, мы подробно остановимся на технических возможностях, относящихся к абстрактным типам данных.
В заключение отметим, что основная специфика ООП связана именно с иерархическими типами данных, поэтому многие вопросы, рассматриваемые в настоящем разделе, имеют отношение и к другим парадигмам программирования и могут быть в той или иной мере знакомы читателю.
Вопросы и задания
Дайте определения следующим терминам и сопоставьте русские термины с английскими: переменная, область видимости переменной, инкапсуляция, структура данных, абстрактный тип данных, класс, модификатор доступа, сокрытие имен, variable, scope, encapsulation, data structure, abstract data type, access modifier, class.
Как соотносятся следующие понятия: принцип сокрытия информации, абстракция, инкапсуляция.
Поясните по рисункам, иллюстрирующим рассмотренную эволюцию языков программирования, каждый из выделенных этапов: какие проблемы предыдущих этапов он решает и какие проблемы сохраняются?
Опишите синтаксис и семантику следующих ключевых слов C#: class, public, private, this.
Опишите различие значимых и ссылочных типов данных в C#.
* Приведите примеры встроенных (в язык программирования) структур данных помимо массивов.
Реализуйте класс комплексного числа. Класс должен поддерживать методы чтения и записи действительной и мнимой части, а также сложения, вычитания и умножения.
** В тексте главы мы не упоминали частый аргумент в пользу разделения программы на методы – повторное использование. Действительно, если фрагмент кода используется несколько раз, то его эффективнее записать однажды, вынеся в отдельный метод. Проиллюстрируйте на рассмотренном примере программы расчета площади треугольника следующие утверждения: 1) руководствуясь стремлением избежать дублирования кода мы, в общем случае, не получим лучшее разделение на методы и соблюдение принципа сокрытия информации; 2) руководствуясь принципом сокрытия информации мы, в общем случае, получим исключение дублирования и эффективное повторное использование кода.
Примечания:
- ↩︎
9. Конечно, надо понимать, что ООП – не всегда лучшее решение. Мы вернемся к этому вопросу в заключении.
- ↩︎
10. «Пользователь» процедуры или метода или класса или кода – это другой код, использующий (вызывающий) эту процедуру или метод или класс или фрагмент кода, либо программист, пишущий этот другой код.
- ↩︎
11. Сигнатура метода – имя метода и перечень его параметров, определяемых типами этих параметров. Имена параметров и тип возвращаемого методом значения не входит в сигнатуру.
- ↩︎
12. Также структура может быть определена в C# ключевым словом struct. Тут есть некоторая терминологическая путаница, забегая вперед скажем, что «структуры» в том смысле, в котором мы обсуждаем их в настоящем параграфе – это «классы» без некоторых возможностей. А структуры в C# имеют другое специфическое для этого языка назначение, мы вернемся к этому вопросу в § 11.
- ↩︎
13. Отметим для сравнения, что в некоторых языках переменную, указывающую на объект, для которого был вызван метод класса (this), необходимо объявлять явно. Например, так работает Python: объявление метода float Length (Point p) из приведенного примера выглядело бы следующим образом: def length (self, p), но при вызове этого метода мы бы писали как и в C#: p1.length(p2). То есть в самом методе self == p1, p == p2.
- ↩︎
14. Иногда используются не вполне точные термины спецификатор (specifier) или квалификатор (qualifier) доступа.
- ↩︎
15. Строго говоря, принцип сокрытия информации формулируется как принцип необходимости скрытия частей программы друг от друга за стабильными интерфейсами, содержащими минимально необходимую информацию.
- ↩︎
16. И не имеет отношение к абстрактным методам класса, которые мы будем рассматривать в главе 3.3.