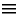
2.2. Жизненный цикл объекта
§ 10. Объекты. В предыдущей главе мы познакомились с понятиями класса (пользовательского типа данных) и объекта (переменной этого типа). Теперь мы рассмотрим в деталях жизненный цикл объекта: кем, когда и как создаются объекты, где и как долго они существуют и кем, когда и как они удаляются. Мы достаточно подробно будем рассматривать модель памяти, то есть то, как именно объекты вашей программы хранятся в оперативной памяти. Рассмотрение этих вопросов важно для понимания того, почему мы работаем с объектами и классами так, а не иначе, для формирования у разработчиков «осязаемого» представления объекта и точного понимания «инструментальных» границ ООП17.
В настоящем параграфе мы обозначим основные вопросы, связанные с жизненным циклом объекта. Начнем с определения «объекта» в узком смысле слова с точки зрения модели памяти.
Объект (object), или объект класса, или экземпляр класса (instance) – в узком смысле слова – это адресуемая одним адресом область памяти для хранения значений всех полей класса.
Любой объект в программе: 1) создается; 2) «живет»; 3) удаляется. Согласно приведенному определению, создание объекта – это выделение и инициализация памяти для хранения значений полей объекта, а удаление объекта – это освобождение памяти, используемой для хранения значений полей объекта. Проиллюстрируем это на примере из предыдущей главы.
Point p = new Point ();
Как мы уже рассматривали, команда new Point() приводит к выделению в памяти области для хранения полей класса Point. Эта область адресуется одним адресом, который сохраняется в ссылочную переменную p. Приведем рисунок, показывающий распределение памяти:
Отметим, что объект может включать в себя другие объекты, например, объект класса круга Circle может содержать объект класса точки Point как свой центр. В этом случае мы можем понимать под объектом как собственно перечень полей класса Circle (в узкой трактовке), так и совокупность этих полей и всех зависящих объектов (в широкой трактовке) – в зависимости от контекста обсуждения.
После создания и до удаления объект «живет» в том смысле, что он существует в памяти. Однако при этом он не обязательно может быть доступен в коде. Мы рассмотрим такие ситуации ниже в параграфе про удаление объектов.
В более широком смысле, можно сказать, что объект – владелец выделенных ему ресурсов вычислительной машины: памяти, файлов, подключений к базе данных, сетевых соединений и других. Соответственно, при создании объект получает эти ресурсы, при удалении – освобождает. При некорректном удалении некоторые из ресурсов могут остаться неосвобожденными. Если это память, то происходит утечка памяти, если файл – блокирование файла для других процессов, если БД – избыточно долгое владение подключением, ограничивающее возможность подключения новых клиентов. При создании и удалении объекта выделение и освобождение ресурса памяти выполняется посредством механизмов языка программирования, а организация работы с прочими ресурсами – задача разработчика.
Термины «объект» и «переменная» используются как синонимы, но переменная чаще используется для обозначения встроенных значимых типов данных, а объект – для ссылочных и пользовательских. Также, говоря об объекте, мы часто делаем акцент на объекте в памяти, а говоря о переменной – на имени этого объекта в программе. В этом смысле, переменная – это именованный объект. Однако в общем случае эти термины используются как синонимы, а конкретное значение определяется контекстом.
Прежде чем начать подробное рассмотрение обозначенных тем, напомним читателю в минимально необходимом объеме некоторые вопросы организации памяти.
§ 11. Стек и куча. Любой объект программы может быть размещен в одной из двух областей памяти: 1) в стеке вызовов (call stack), стеке, или 2) в динамической памяти (dynamic memory), куче (heap).
Рассмотрим сначала выделение и освобождение памяти на уровне отдельного метода. Переменные-параметры метода и переменные, объявленные в методе, называются локальными переменными метода. При компиляции программы компилятор всегда знает, какой объем памяти потребуется для хранения значений локальных переменных, понимая под значением непосредственное значение переменной: в случае значимого типа – само значение, в случае ссылочного типа – адрес. Объем требуемой памяти всегда известен, так как 1) все переменные объявлены; 2) все переменные типизированы, а каждый тип требует определенного объема памяти. При этом, конечно, размеры объектов, указатели на которые хранят ссылочные переменные, на этапе компиляции вполне могут быть неизвестны.
Рассмотрим упрощенно процесс вызова метода. При вызове метода в специальной области памяти – стеке – резервируется память для всех локальных переменных метода. В переменные-параметры записываются передаваемые в метод значения. Далее, управление передается методу вместе с адресом стека. Если метод, в который передано управление, в свою очередь, вызывает другой метод, то процедура повторяется. Когда же метод возвращает значение, он записывает результат в стеке, а часть стека, относящаяся к выполняемому методу, удаляется и управление передается вызвавшему методу. Покажем описанный процесс на классическом примере рекурсивного метода расчета факториала:
void f (int n)
{
if (n == 1) return 1;
return n * f (n - 1);
}
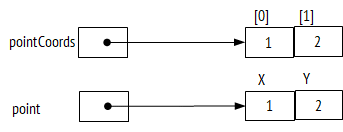
Следующий рисунок упрощенно демонстрирует последовательность состояний стека при вызове f (3):
На рисунке каждый из пяти показанных блоков памяти – это состояние стека в разные моменты выполнения программы. Сначала (верхний левый блок) при входе в метод f (3) в стеке размещается ячейка для хранения параметра этого метода (n=3) и ячейка для записи возвращаемого значения (ret). Далее, из этого метода вызывается метод f (2). При входе в метод стек дополняется ячейкой для хранения параметра (n=2) и ячейкой для возврата результата. Далее, из f (2) вызывается f (1). И стек дополняется еще двумя ячейками. В методе f (1) записывается возвращаемое значение в ячейку ret стека (нижний левый блок на рисунке). Управление возвращается методу f (2). Аналогично управление возвращается методу f (3) и в стеке снова остается две ячейки.
Мы ожидаем, что читатель уже знаком с этим механизмом, поэтому здесь приводится краткое, тезисное описание. Для понимания дальнейшего материала важно вполне разобраться с приведенным примером, прежде чем продолжать чтение.
Память для локальных переменных выделяется и освобождается автоматически и в строго определенные моменты времени – при входе и выходе из метода. Однако, это не значит, что при входе в метод все локальные переменные автоматически создаются, так как, как мы уже указали, создание – это выделение памяти и инициализация. В этом смысле при входе в метод создаются только переменные-параметры. Для остальных локальных переменных память выделяется, но они считаются созданными только после явной инициализации объекта, то есть присвоения начального значения18. В C# инициализацию локальных переменных должен явно выполнять программист. До того, как выполнена инициализация, использование переменной (чтение ее значения) запрещено, так как создание объекта еще не завершено.
int a;
a++; // Ошибка при компиляции, т.к используется неинициализированный объект.
a = 1;
a++; // Тут объект уже создан и его можно использовать.
Также отметим, что следует различать область видимости (scope) и время жизни (lifetime) объекта. Объект «жив» до тех пока он не удален и, соответственно, владеет некоторыми ресурсами, как минимум, занимает память. Однако объект может быть еще «жив», но уже не виден ни из какой части программы:
void SomeMethod()
{
int count = 0;
for (int i = 0; i < 10; i++)
{
count += i;
}
// Ошибка при комплияции.
// Память для переменной i выделяется при входе в метод в стеке.
// Переменная i инициализируется при объявлении в строке for.
// Таким образом переменная i здесь в некотором смысле «жива».
// НО: здесь переменная находится вне области видимости.
Console.WriteLine (i);
}
При работе со ссылочными переменными объект-значение, на который указывает адрес, хранимый в переменной, сохраняется в динамической памяти, которая выделятся при создании объекта оператором new. Рассмотрим следующий пример:
void SomeMethod()
{
int[] arr = new int[2];
arr[0] = 1;
arr[1] = 2;
arr = new int[2];
arr[0] = 3;
arr[1] = 4;
Point p = new Point(5, 5);
}
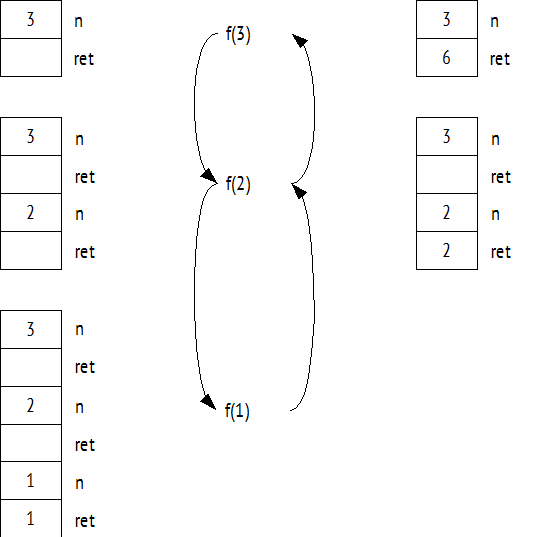
Распределение памяти для приведенного кода показано на следующей схеме:
Обратим внимание, что при выходе из метода локальные переменные удаляются автоматически, но объекты-значения, на которые указывали локальные ссылочные переменные остаются «жить» в динамической памяти. Вопрос об их удалении мы будет рассматривать в последующих параграфах, сейчас лишь зафиксируем момент, что автоматического удаления не происходит.
Зададимся вопросом: можем ли мы разместить переменную пользовательского типа, например, Point, в стеке? Ответ зависит от используемого языка программирования. В C# ссылочные переменные (экземпляры классов) всегда размещаются в динамической памяти. Однако мы можем создать специальный пользовательский тип, называемый в C# структурой. Переменные этого типа будут значимыми, соответственно, локальные переменные этого типа будут создаваться в стеке:
class PointClass { public float X; public float Y; }
struct PointStruct { public float X; public float Y; }
void SomeMethod()
{
PointClass p1 = new PointClass();
p1.X = 1;
p1.Y = 1;
PointStruct p2;
p2.X = 2;
p2.Y = 2;
}
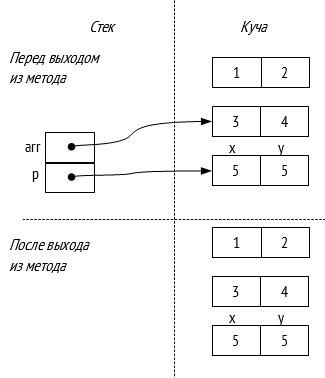
Размещение объектов памяти представлено на следующей схеме:
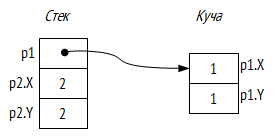
Отметим, что во втором случае мы не используем оператор new19, а синтаксис аналогичен объявлению значимой переменной. Также, отметим, что при выходе из метода объект p2 удаляется, а p1 – остается «жив». Структуры в C# целесообразно применять только в определенных обстоятельствах, в первом приближении следует руководствовать правилом: всегда используйте классы.
Другие языки программирования могут позволять размещать объект в стеке или динамической памяти на выбор программиста. Например, рассмотрим следующий код на C++:
// С++
// в стеке
int x;
// не нужно использовать оператор new, синтаксис идентичен определению x.
Point p;
// в куче
Point* p2 = new Point();
p2->X = 5;
В заключение, отметим частую ошибку, допускаемую при изучении способов размещения переменных в динамической памяти или стеке: значимые переменные не обязательно размещаются в стеке. Так, значимая переменная может быть полем класса и тогда она вместе с другими полями класса – как в рассмотренных примерах – будет создана в динамической памяти.
В следующем параграфе мы подробно рассмотрим процедуру создания объектов.
§ 12. Создание объектов. При создании (конструировании) объекта оператором new автоматически выполняется определенная последовательность действий. Перечислим все шаги и далее рассмотрим каждый из них подробно.
1. Выделяется память для всех полей объекта.
2. Все поля объекта инициализируются или указанными явно значениями, или значениями по умолчанию для соответствующего типа данных.
3. Вызывается специальный метод класса – конструктор.
4. Возвращается адрес созданного объекта.
Если поля класса просто объявлены – как мы делали во всех рассмотренных ранее примерах, то на шаге 2 поля инициализируются значениями по умолчанию. Для значимых типов данных – чисел это 0, для bool – false, для ссылочных типов данных – null20.
class Circle
{
public Point Center;
public float R;
}
Circle c = new Circle ();
// Здесь: c.R == 0 && c.Center == null.
Однако программист может явно задать требуемое значение поля по умолчанию в объявлении поля:
class Circle
{
public Point Center = new Point ();
public float R = 1;
}
На шаге 3, после инициализации полей, вызывается специальный метод – конструктор. В конструкторе может быть реализована дополнительная логика, также конструктор может инициализировать поля согласно передаваемым в этот конструктор параметрам. Метод-конструктор может быть вызван только при создании объекта, имя конструктора должно совпадать с именем класса, при этом у конструктора не указывается возвращаемое значение21.
public Point
{
private float x;
private float y;
// Конструктор.
public Point(float x, float y)
{
this.x = x;
this.y = y;
}
}
Point p = new Point (1, 2);
// Здесь p.x == 1 && x.y == 2.
Конструкторы, как и обычные методы, могут быть перегружены, то есть в классе может быть несколько конструкторов, в том числе, конструктор без параметров.
public Point
{
private float x;
private float y;
public Point(float x, float y)
{
this.x = x;
this.y = y;
}
public Point()
{
x = 1;
y = 1;
}
}
Конструктор без параметров называется конструктором по умолчанию (default constructor). Если в классе не объявлен ни один конструктор, конструктор по умолчанию создается неявно автоматически22, то есть следующие объявления классов эквивалентны:
public Point { }
Point p = new Point();
public Point { public Point() { } }
Point p = new Point();
Однако если мы определяем хотя бы один конструктор, то неявный конструктор по умолчанию становится недоступным:
Public Point { public Point (float x, float y) { … } }
// ошибка компиляции: не существует конструктор Point ();
Point p = new Point ();
Обратим внимание, что синтаксис создания объекта представляет собой вызов оператора new для конструктора:
Triangle = new Triangle (p1, p2, p3);
Из конструктора можно вызывать другой конструктор (для того же самого создаваемого объекта) только с использованием специального синтаксиса:
public Circle
{
public Circle (Point p, float r)
{
Center = p;
R = r;
}
// Сначала выполняется вызов другого конструктора:
// Circle (Point p, float r)
public Circle (float x, float y, float r) : this (new Point (x, y), r)
{
// Потом управление передается в тело вызыванного конструктора.
}
}
Метод-конструктор можно вызвать через оператор new при создании объекта или из другого конструктора того же класса, как в приведенном примере, и никак иначе.
В заключение обратим внимание, что выполнение оператора new и присваивание возвращаемого им значения (ссылки на созданный объект) переменной – независимые операции, поэтому оператор new может быть вызван без присвоения возвращаемого значения:
new Point (1, 5);
(new Point()).X = 5;
Смысла в приведенных строках нет, однако иногда такой подход используется, когда нам нужно однажды вызвать некоторый метод класса.
Рассмотренный процесс создания объекта в разных языках отличается в деталях, но в целом описанные этапы и понятие конструктора одинаковы для современных объектно-ориентированных языков.
§ 13. Удаление объектов. В предыдущих параграфах мы отмечали, что при выходе из метода удаление объектов из стека выполняется автоматически, а объекты, размещенные в динамической памяти, автоматически не удаляются. Чем обусловлено такое поведение? Дело в том, что на объект в динамической памяти могут указывать разные переменные и, в общем случае, на этапе компиляции нет способа определить, в какой момент времени объект в динамической памяти больше не нужен никому и его можно удалить. Соответственно, есть два решения: или обязать программиста вручную вызывать команду удаления объекта (так как программист при написании приложения всегда может определить, когда объект больше не нужен), или на этапе выполнения периодически просматривать динамическую память, находить объекты, на которые нет указателей в программе и удалять их. Используемый вариант зависит от языка программирования.
Рассмотрим сначала вариант ручного удаления. Так, в С++ программист сам ответственен за освобождения памяти и должен вызывать оператор delete.
// C++
Point* p = new Point();
// ...
delete p;
При вызове оператора delete в памяти освобождается место, занятое его полями. Но что происходит, если поле объекта, в свою очередь, указывает на другой объект? Рассмотрим следующий пример:
//С++
class Circle
{
private:
Point* center;
float radius;
}
При вызове оператора delete память, занятая полями будет освобождена, но память, занятая объектом центром останется занятой, а объект Point* center останется «жив». На следующем рисунки заштрихована освобожденная память

Поэтому по аналогии с тем, что иногда требуется специальный метод, реализующий логику инициализации объекта (конструктор), может потребоваться специальный метод, реализующий логику удаления объекта. Такой метод называется деструктором.
Деструктор (destructor) – метод, автоматически вызываемый непосредственно перед удалением объекта (освобождением занимаемой им памяти).
В классе может быть только один метод-деструктор, и он никогда не имеет параметров. Имя метода совпадает с именем класса, но перед ним ставится символ «тильда». Такой синтаксис используется в C++ и в C#, однако в C# деструкторы называются финализаторами (finalizer) и имеют свою специфику, их мы рассматривать не будем:
// C++
class Circle
{
public ~Circle()
{
delete center;
}
}
Таким образом, ручное удаление объекта состоит из следующих шагов: 1) вызывается деструктор объекта (явно программистом); 2) освобождается память, занятая всеми полями объекта (автоматически неявно).
При удалении объектов мы решаем две задачи: 1) программирование корректной процедуры удаления самого объекта и всех объектов – его частей; 2) запуск этой процедуры удаления.
Возлагая решение и первой, и второй задачи на программиста, мы даем ему максимальный контроль над памятью и производительностью, но появляется некоторая рутинная задача, что неизбежно приводит к трудноулавливаемым ошибкам. Что произойдет, если программист забудет удалить некоторый объект? Тогда и на этапе компиляции, и на этапе выполнения не будет никаких ошибок, но произойдет утечка памяти (memory leak) – появление в ходе выполнения программы областей памяти, выделенных программе, но больше не используемых ею.
Каким образом возможно организовать автоматическое удаление? В C# оператор delete отсутствует, программист не задумывается, когда и какой объект ему нужно удалить, а объекты, на которые больше нет ни одной ссылки, удаляются автоматически сборщиком мусора.
Сборка мусора (garbage collection, GC) – процедура автоматического удаления объектов, на которых нет ссылок.
Выполнение вашей программы периодически прерывается и специальное приложение – сборщик мусора (garbage collector) – определяет объекты (участки выделенной программе памяти), на которые больше нет указателей (нет ни одной ссылочной переменной, указывающей на этот объект) и удаляет их (освобождает выделенную память). При этом момент времени, когда запускается сборщик мусора не детерминирован (с точки зрения разработчика), соответственно, может возникнуть ситуация, когда при выполнении критичной по производительности операции программа будет приостановлена и сборщик мусора некоторое время будет выполнять очистку. В некоторых случаях это неприемлемо, однако для большинства приложений эти издержки окупаются повышением надежности и простоты.
Отметим, что сборка мусора полностью решает вторую задачу удаления объектов (запуск удаления) и отчасти первую (процедура удаления). Мы говорим «отчасти», так как сборщик мусора может определить какую память необходимо освободить, но не может корректно освободит другие ресурсы, занятые объектом.
К каким издержкам может привести сборка мусора, кроме возможности приостановки приложения в непредсказуемые моменты времени? При ручном удалении мы можем удалять объекты, как только они нам больше не нужны. Как следствие, мы можем обеспечить режим, при котором программа будет использовать в каждый момент времени минимально необходимый ей объем памяти. В случае же сборки мусора всегда будут периоды времени, когда в памяти уже есть ненужные объекты, но они еще не удалены сборщиком мусора, соответственно, средний уровень расходования памяти будет выше. Отметим, что в случае стека у нас тоже возможны периоды времени, когда переменная больше не нужна, но существует в стеке до выхода из метода. Как следствие, если у нас большие методы, то это может привести к повышенному расходованию памяти. Однако стоимость добавления и удаления объектов в стеке крайне мала, а методы не следует делать избыточно большими по многим причинам, из которых причина производительности – на последнем месте.
§ 14. Механизм сборки мусора. Рассмотрение механизма сборки мусора выходит за рамки книги, поэтому мы ограничимся описанием общего принципа. Процедура сборки мусора может оказаться достаточно сложной и ресурсоемкой: во-первых, нужно найти и удалить ненужные приложению объекты (пометить соответствующую память как свободную). Во-вторых, используемую память нужно дефрагментировать, иначе фрагментация через какое-то время не позволит создавать новые объекты. Например, рассмотрим пример, приведенный на следующем рисунке. Области занятой памяти обозначены штриховкой. Мы видим, что суммарного объема свободной памяти достаточно, чтобы разместить новый объект, показанный сверху. Однако из-за фрагментации, его разместить не удастся, так как нет непрерывной области свободной памяти необходимого размера.

При этом регулярная дефрагментация всей памяти приложения – очень «дорогая» операция. Общий подход к решению этой проблемы основан на факте, что большинство объектов – короткоживущие. Рассмотрим несколько упрощенный типичный алгоритм сборки мусора.
Создаваемые объекты добавляются в области памяти первого поколения (1 generation) друг за другом без учета освобождаемых областей до тех пор, пока для добавления нового объекта не оказывается свободного места (шаг 1 на следующем рисунке). Когда это происходит, выполнение программы прерывается, и сборщик мусора выполняет дефрагментацию памяти первого поколения, а также помечает «выжившие» объекты числом, обозначающим количество «пережитых» сборок мусора – в данном случае числом 1 (шаг 2). Выполнение программы возобновляется, память выделяется также в области первого поколения, и описанная последовательность шагов повторяется.
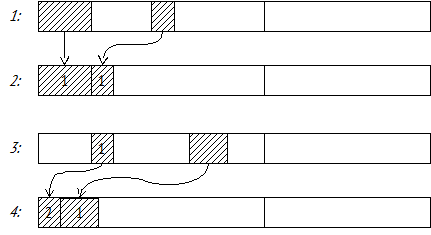
Далее, объекты, которые пережили большое число сборок мусора, перемещаются в другую область памяти – второе поколение. Она обрабатывается так же, как память первого поколения.
Так как большинство объектов короткоживущие, то они будут удаляться из 1 поколения быстро, редко попадая в дефрагментацию. Долгоживущие же будут перемещаться во 2-е, где сборка мусора срабатывает редко. Таким образом, удается минимизировать необходимый объем перемещаемых данных при дефрагментации.
Несмотря на автоматизацию сборка мусора – это процесс, который всегда следует иметь в виду. Нередко разработчик, программируя на языке с автоматической сборкой мусора, начинает расточительно создавать и пересоздавать объекты, что приводит к неоправданно большому объему используемой памяти или ощутимым задержкам («фризам») при срабатывании сборщика мусора в процессе выполнения программы.
Вопросы и задания
Дайте определения следующим терминам и сопоставьте русские термины с английскими: объект, экземпляр, переменная, локальная переменная метода, стек, динамическая память, куча, подъем объявления переменной, конструктор, конструктор по умолчанию, конструктор без параметров, деструктор, сборка мусора, утечка памяти, object, instance, variable, local variable, stack, heap, hoisting, constructor, default constructor, parameterless constructor, destructor, finalizer, garbage collection, memory leak.
Какая переменная считается созданной?
Приведите примеры кода на C#, в которых: 1) значимая переменная создается в стеке; 2) значимая переменная создается в динамической памяти.
Максимальный размер стека, как правило, ограничен несколькими мегабайтами. При этом размер динамической памяти ограничен только объемом физической оперативной памяти компьютера23. Напишите программу, выполнение которой приводит к ошибке переполнения стека. (StackOverflowException).
Объясните, почему на практике разработчики крайне редко сталкиваются с недостаточным объемом стека несмотря на его крайне ограниченный размер по сравнению с объемами доступной физической оперативной памяти.
Создайте класс, который выводит в консоль сообщение до вызова любого своего конструктора.
Возможно ли вызывать из обычного метода класса конструктор для того же объекта того же класса?
Конструктор может быть как открытым (public), так и закрытым (private). Приведите пример, когда целесообразно использовать закрытый конструктор.
Положим, у нас есть класс круг Circle, который хранит свой центр в поле типа Point (мы рассматривали этот пример в тексте главы). Положим, у нас есть переменная circle типа Circle, которая в текущий момент выполнения программы нигде не используется. Также, нигде не осталось прямых ссылок и на центр круга этой переменной. При срабатывании сборки мусора детерминирована ли последовательность освобождения памяти: сначала будет освобождена память, занимаемая центром круга (координаты) или память, занимаемая полями круга (радиус и ссылка на центр)?
В продолжение предыдущего вопроса: положим в текущий момент выполнения программы нигде не осталось ссылок на переменную circle, однако есть прямая ссылка на центр круга. При срабатывании сборки мусора, будут ли удалены данные, относящиеся к кругу (радиус и ссылка на центр)?
Сравните минимальный, средний и максимальный объем используемой памяти аналогичными приложениями 1) со сборкой мусора; 2) с ручным освобождением памяти, выполняемым программистом.
Почему в общем случае выделение и освобождение динамической памяти существенно «дороже» (занимает больше времени), чем выделение и освобождение памяти в стеке?
Примечания:
- ↩︎
17. Отметим, что, к примеру, при изучении логического программирования, например, таких языков как Prolog или Lisp, или при изучении функционального программирования, например, F#, вопросам модели памяти уделяется существенно меньше внимания, так как эти парадигмы программирования предполагают существенно больший уровень абстракции по сравнению с ООП. Однако в ООП «расстояние» между исходным кодом и формируемым на его основе машинным кодом значительно меньше и у разработчика есть значительно больше инструментов влиять (в хорошую или плохую сторону) на низкоуровневые процессы при выполнении приложения.
- ↩︎
18. Отметим, что во многих языках программирования реализован подъем объявления переменной (variable hoisting), то есть независимо от того, где в методе вы объявили переменную, она создается, инициализируется и, главное, видна с начала метода, например, подобная логика реализована в JavaScript и Visual Basic.
- ↩︎
19. Строго говоря, мы могли бы использовать оператор new, но в случае структур в C# он выполняет инициализацию всех полей структуры значениями по умолчанию для соответствующего типа данных.
- ↩︎
20. В C# все эти варианты физических сохраняются как 0.
- ↩︎
21. Обратим внимание, что синтаксис метода-конструктора можно интерпретировать и наоборот: не как метод без возвращаемого типа с именем, совпадающим с именем класса, а как метод без имени с возвращаемым типом – текущим классом.
- ↩︎
22. Отметим, что конструктор по умолчанию так называется именно потому, что он создается неявно если в классе не объявлен никакой другой конструктор, то есть по умолчанию. Объявленный же явно конструктор без параметров называется или также конструктором по умолчанию, или конструктором без параметров (parameterless constructor). Оба термина широко используются, мы далее для единообразия будем использовать только первый.
- ↩︎
23. Строго говоря, приложения, компилируемые не в машинный, а в промежуточный код, например, приложения, написанные на .NET (C#) или Java, получают динамическую память не напрямую у операционной системы, а у среды исполнения (CLR или JRE соответственно). При этом максимальный объем памяти, который они могут запросить может быть ограничен со стороны среды исполнения и, следовательно, может быть существенно меньше физически располагаемого объема памяти и зависит от конфигурации.